A quick glance at the capabilities of Karnataka Data Lake with respect to different users can be found here: http://kdl.iiitb.ac.in/index.php/quick-glance/
Looking at the massive data needs of the Planning Department, Karnataka Data Lake, a Policy Support System is proposed to create a dedicated Big Data Lake for the planning department to integrate and consume this data for Diagnosis, Prediction, Forecast, and Recommendations automatically. Below is the pipeline architecture for the system :
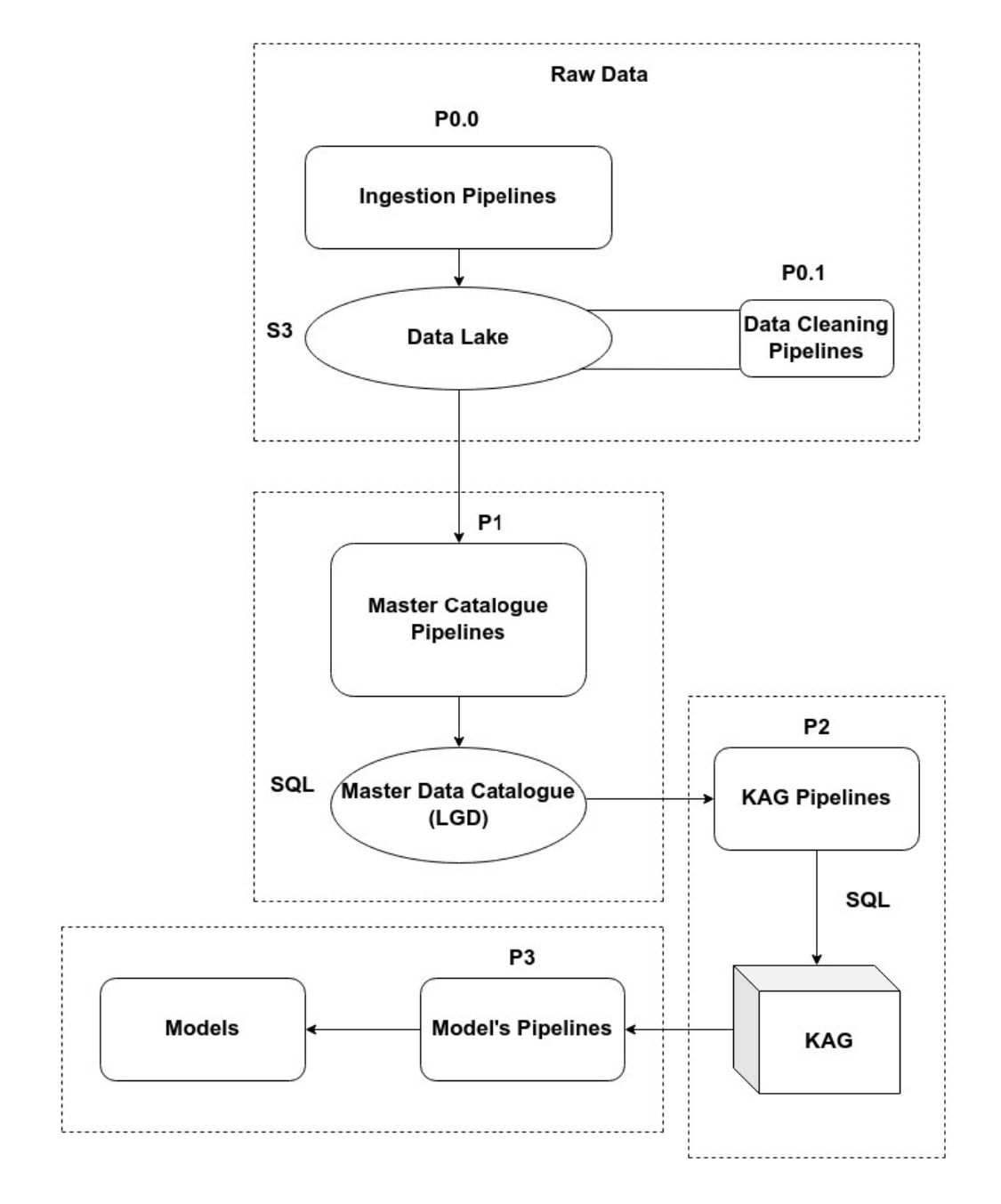
P0: The component is meant to process datasets and perform operations like data cleaning, semantic resolution, canonicalization, etc. A set of scripts ingest a wide variety of data such as structured, semi-structured, unstructured, or binary data into a data lake from disparate open data sources. It is equipped with a flat architecture, where every data element in the lake is given a unique identifier and tagged with a set of metadata information.
P1: The component uses the cleaned/formatted/pre-processed raw data from P0 and generates master data tables by performing statistical operations/transformations/aggregations/joins and deriving new data by utilizing the templates provided by Gok. Thus forming a Master data catalog gives useful domain insights for any level of geospatial entities by including LGD code.
P2: This component maps the master files into respective data marts (each represents a domain) from which abstract reports of each domain are generated.
P3: Bayesian Networks can provide clues on how and where to intervene with policy instruments so as to achieve targets in the best possible way. We are developing models combining available external knowledge about the domain, with ML tools that can learn dependency parameters. The models accommodate uncertainty and permit geospatial data analysis